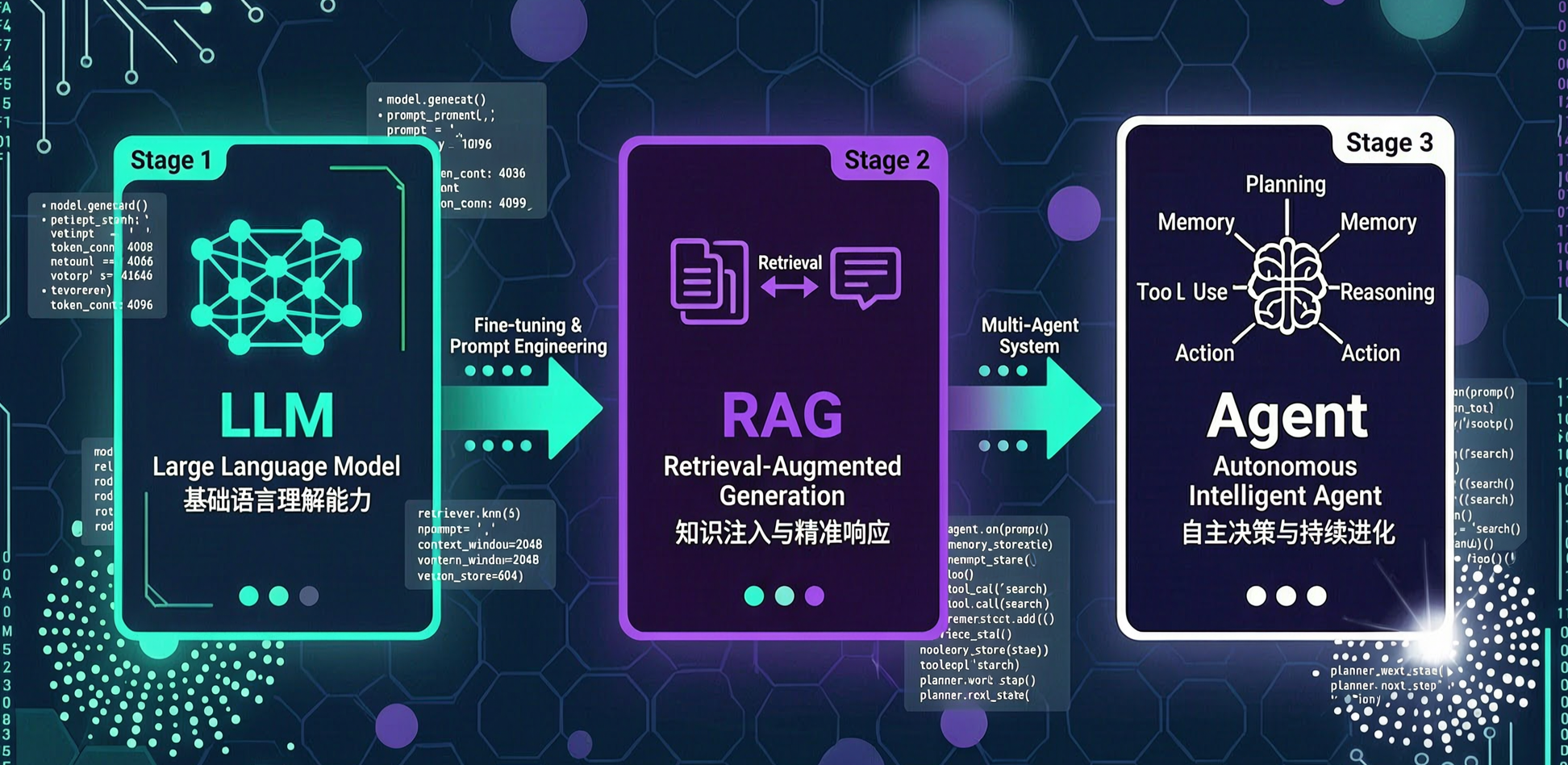
1. 引言:从提示词工程到系统工程的范式转移
在 AI Agent 迈向生产环境的过程中,开发者往往会陷入“提示词迷思”,试图通过无限堆砌 Prompt 来覆盖业务边界。然而,由于大模型本质上的概率性,纯粹的提示词工程在面对长链条任务、复杂工具调用和状态一致性要求时,往往表现出极高的脆弱性。
作为架构师,我们必须清醒地认识到:Agent 的落地不仅仅是算法的博弈,更是严谨的系统工程。要实现从原型到工业级应用的飞跃,必须建立一套能够约束不确定性的“稳固支架”。这就是 Harness 架构 的核心哲学:
“Harness 并非业务逻辑本身,而是保障流程稳健、可验证的工业底座。其核心思想是:Agent 的每一次犯错都不应被视为偶然的失败,而应转化为对环境架构的持续修复与沉淀。”
将状态作为一等公民,利用传统高并发后端架构的 ACID 特性或最终一致性模式来治理模型输出,是 Agent 工业化的必经之路。
2. Harness 架构的六大支柱:构建稳健的 Agent 环境
Harness 架构通过六个维度为 Agent 提供标准化的运行边界。当系统失效时,架构师应定位至特定的支架进行硬性加固, ...