langchain中的chain到底是什么
一、Chain 是什么
Chain 是 LangChain 中组件串联执行的核心机制,它将多个独立组件(提示词模板、模型、工具等)按顺序连接,前一个组件的输出自动作为下一个组件的输入,实现复杂任务的流水线化处理。
二、核心特性
- 链式语法:通过
|符号快速拼接组件,写法简洁直观
1 | chain = chat_prompt_template | model # 提示词模板 → 模型 |
- 接口约束:参与成链的组件必须是
Runnable接口的子类(如提示词模板、模型、嵌入模型等) - 对象类型:最终形成的链是
RunnableSerializable对象,本身也实现了Runnable接口,可继续参与链式拼接 - 执行触发:通过
invoke()(一次性执行)或stream()(流式执行)触发整个链条运行
三、执行流程
- 输入:传入字典格式参数(如
{"history": "历史对话", "input": "用户问题"}) - 组件 1:提示词模板:将输入参数填充到模板中,生成
PromptValue(完整提示词文本) - 组件 2:模型对象:接收提示词文本,调用大模型生成回复
- 输出:返回模型回复的
AIMessage对象(或流式 chunk)
1 | 输入字典 → chat_prompt_template → PromptValue → model → AIMessage |
四、可加入的组件

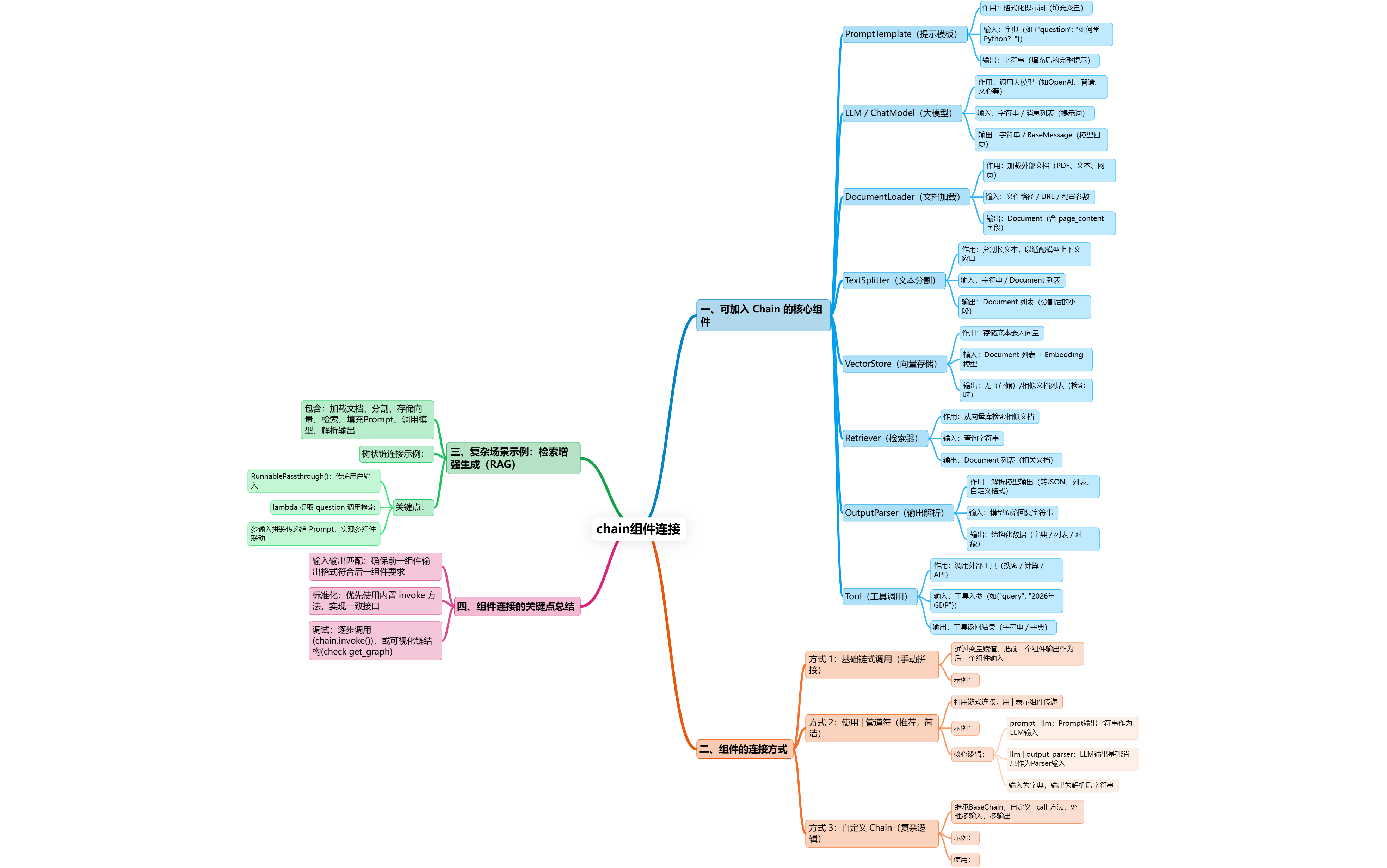
LangChain 的链(Chain)本质是 Runnable 接口组件的流水线,只要实现 **Runnable** 接口(或通过封装适配),任何组件 / 逻辑都能加入,以下是完整分类总结(重点补充自定义函数):
一、可加入 Chain 的核心组件
LangChain 的组件都遵循「输入→处理→输出」的标准化逻辑,核心可接入 Chain 的组件分为以下几类,先明确每类的核心作用和接口:
| 组件类型 | 核心作用 | 标准输入(Input) | 标准输出(Output) |
|---|---|---|---|
| PromptTemplate | 格式化提示词(填充变量) | 字典(如 {"question": "如何学Python?"}) |
字符串(填充后的完整提示词) |
| LLM/ChatModel | 调用大模型(OpenAI / 智谱 / 文心等) | 字符串 / 消息列表(提示词) | 字符串 / BaseMessage(大模型回复) |
| DocumentLoader | 加载外部文档(PDF / 文本 / 网页) | 文件路径 / URL / 配置参数 | Document 列表(含 page_content 字段) |
| TextSplitter | 分割长文本(适配模型上下文窗口) | 字符串 / Document 列表 | Document 列表(分割后的小片段) |
| VectorStore | 向量存储(存储文本嵌入向量) | Document 列表 + Embedding 模型 | 无(存储)/ 相似文档列表(检索时) |
| Retriever | 从向量库检索相似文档 | 查询字符串 | Document 列表(检索到的相关文档) |
| OutputParser | 解析模型输出(转 JSON / 列表 / 自定义格式) | 字符串(模型原始回复) | 字典 / 列表 / 自定义对象(结构化结果) |
| Tool | 调用外部工具(搜索 / 计算 / API) | 工具入参(如 {"query": "2026年GDP"}) |
工具返回结果(字符串 / 字典) |
二、组件的连接方式
连接组件的核心是「让前一个组件的输出,匹配后一个组件的输入」,LangChain 提供了 3 种主流方式,从简单到复杂依次是:
方式 1:基础链式调用(手动拼接,适合新手)
直接通过变量赋值,把前一个组件的输出作为后一个的输入,逻辑最直观。
1 | from langchain.prompts import PromptTemplate |
方式 2:使用 | 管道符(LangChain 推荐,简洁)
LangChain 支持用 | 符号直接串联组件(类似 Linux 管道),自动处理输入输出的适配,是最常用的方式。
1 | # 基于上面的组件,用管道符串联成链 |
核心逻辑:
prompt | llm:Prompt 输出的字符串自动作为 LLM 的输入;llm | output_parser:LLM 输出的 BaseMessage 自动作为 Parser 的输入;- 整个链的输入是 Prompt 所需的字典,输出是 Parser 处理后的字符串。
方式 3:自定义 Chain(适合复杂逻辑)
如果组件间的逻辑不是简单的「一对一」(比如需要分支、循环、多输入),可以继承 BaseChain 自定义。
1 | from langchain_core.chains import BaseChain |
三、复杂场景示例:检索增强生成(RAG)链(多组件串联)
实际开发中最常用的「RAG 链」就是多组件连接的典型,完整示例如下(覆盖加载→分割→检索→调用模型):
1 | from langchain_community.document_loaders import TextLoader |
关键说明:
RunnablePassthrough():透传输入变量(比如用户的问题);lambda x: retriever.invoke(x["question"]):从输入中提取 question,调用检索器得到 context;- 最终给 Prompt 传入
context(检索结果)和question(用户问题),实现多组件的联动。
四、解决组件连接的核心要点
- 输入输出格式匹配:
-
- 前一个组件的输出必须是后一个的输入格式(比如 Prompt 输出字符串 → LLM 输入字符串);
- 多输入时用「字典 + lambda/RunnablePassthrough」拆分 / 透传变量。
- 标准化组件:
-
- 优先使用 LangChain 内置的
Runnable组件(所有核心组件都实现了invoke方法); - 自定义组件时,实现
invoke方法,保证输入输出标准化。
- 优先使用 LangChain 内置的
- 调试技巧:
-
- 用
chain.invoke()单步调用,查看每个组件的输出; - 用
chain.get_graph()可视化链的结构,检查连接是否正确。
- 用
评论