Haspmap扩容原理剖析
一、为什么需要扩容?
HashMap 底层是一个 数组 + 链表/红黑树 的结构。数组长度是固定的,随着元素不断插入,哈希冲突概率增大,链表越来越长,查询效率从 O(1) 退化为 O(n)。
为了维持高效的查询性能,HashMap 在元素数量达到一定阈值后会自动进行扩容(resize)。
二、核心参数
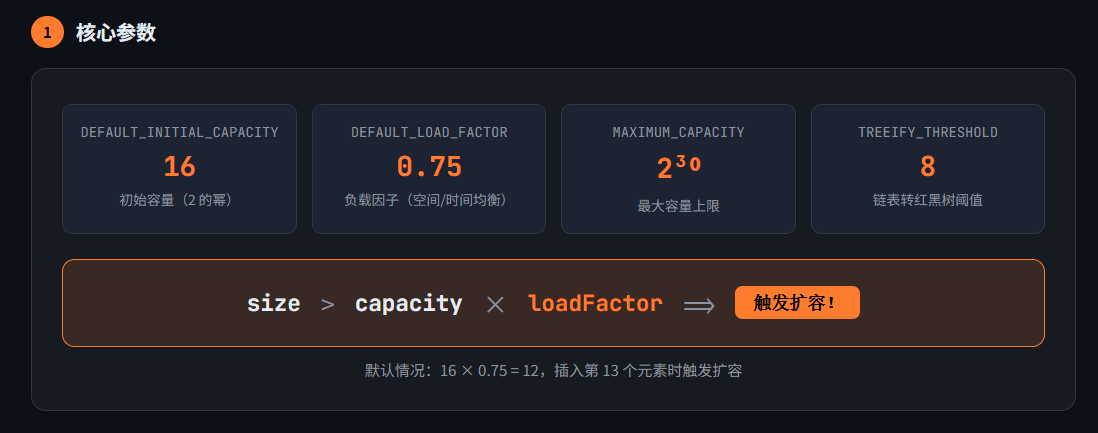

| 参数 | 默认值 | 说明 |
|---|---|---|
DEFAULT_INITIAL_CAPACITY |
16 | 初始容量,必须是 2 的幂 |
DEFAULT_LOAD_FACTOR |
0.75f | 负载因子 |
MAXIMUM_CAPACITY |
2^30 | 最大容量 |
threshold |
capacity × loadFactor | 扩容阈值 |
扩容触发条件:
1 | 当前元素数量(size)> threshold(容量 × 负载因子) |
默认情况下:16 × 0.75 = 12,即插入第 13 个元素时触发扩容。
三、扩容策略:容量翻倍
 编辑
编辑
每次扩容,新数组容量 = 旧容量 × 2。
1 | // JDK 8 源码(resize 方法节选) |
容量始终保持 2 的幂次方,这是 HashMap 设计的核心约束,与后续的位运算寻址密切相关。
四、扩容全过程(JDK 8)
4.1 resize() 方法整体流程
1 | final Node<K,V>[] resize() { |
4.2 数据迁移(rehash)
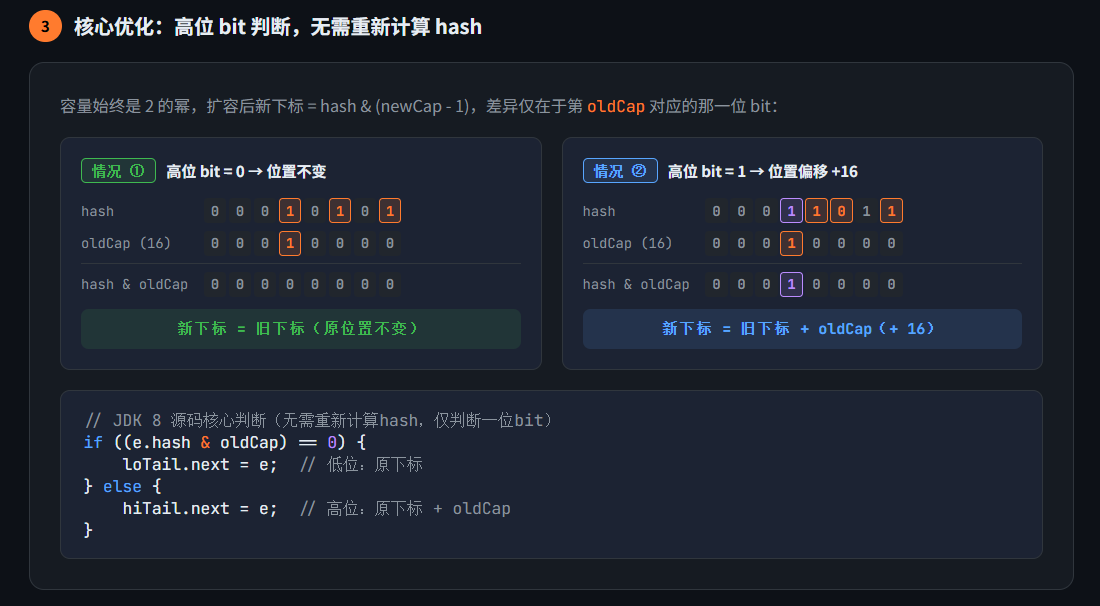 编辑
编辑
扩容后,所有元素需要重新计算在新数组中的位置。
JDK 8 的优化: 利用容量是 2 的幂次这一特性,元素在新数组中的位置只有两种情况:
- 原位置不变:新增高位 bit 为 0
- 原位置 + 旧容量:新增高位 bit 为 1
1 | // 判断高位 bit |
这个设计避免了重新计算 hash,极大提升了扩容效率。
图示说明(以 oldCap=16 为例):
五、链表与红黑树的处理
JDK 8 中,链表长度 ≥ 8 时会转为红黑树。扩容时对两种结构分别处理:
5.1 链表拆分
1 | // 将链表拆分为两条:lo(低位)和 hi(高位) |
5.2 红黑树拆分
红黑树同样按高低位拆分。拆分后:
- 若子树节点数 ≤ 6,退化回链表(
untreeify) - 若节点数 > 6,重新构建红黑树(
treeify)
六、疑问
JDK 7 与 JDK 8 扩容对比
| 对比项 | JDK 7 | JDK 8 |
|---|---|---|
| 数据结构 | 数组 + 链表 | 数组 + 链表 + 红黑树 |
| 插入方式 | 头插法 | 尾插法 |
| rehash 方式 | 重新计算 hash 位置 | 位运算优化,无需重新 hash |
| 并发问题 | 头插法导致死循环 | 尾插法规避了死循环问题 |
⚠️ JDK 7 头插法的并发危险:多线程扩容时,头插法可能导致链表成环,引发
get()死循环。JDK 8 改为尾插法解决了这一问题,但 HashMap 仍非线程安全,多线程场景请使用ConcurrentHashMap。
负载因子为什么是 0.75?
这是空间与时间的权衡:
- 过小(如 0.5):扩容频繁,空间浪费多,但冲突少
- 过大(如 1.0):内存利用率高,但冲突多,链表变长,查询慢
- 0.75:在泊松分布下,桶中元素碰撞概率较低,综合性能最优
官方注释中也提到,在理想随机 hash 下,0.75 的负载因子使得链表长度超过 8 的概率约为 0.00000006,极低。
初始容量的选择?
如果能预估元素数量,建议手动指定初始容量,避免多次扩容带来的性能损耗:
1 | // 预计存放 1000 个元素 |
或者直接使用 Guava 的工具方法:
1 | // Guava |
七、总结
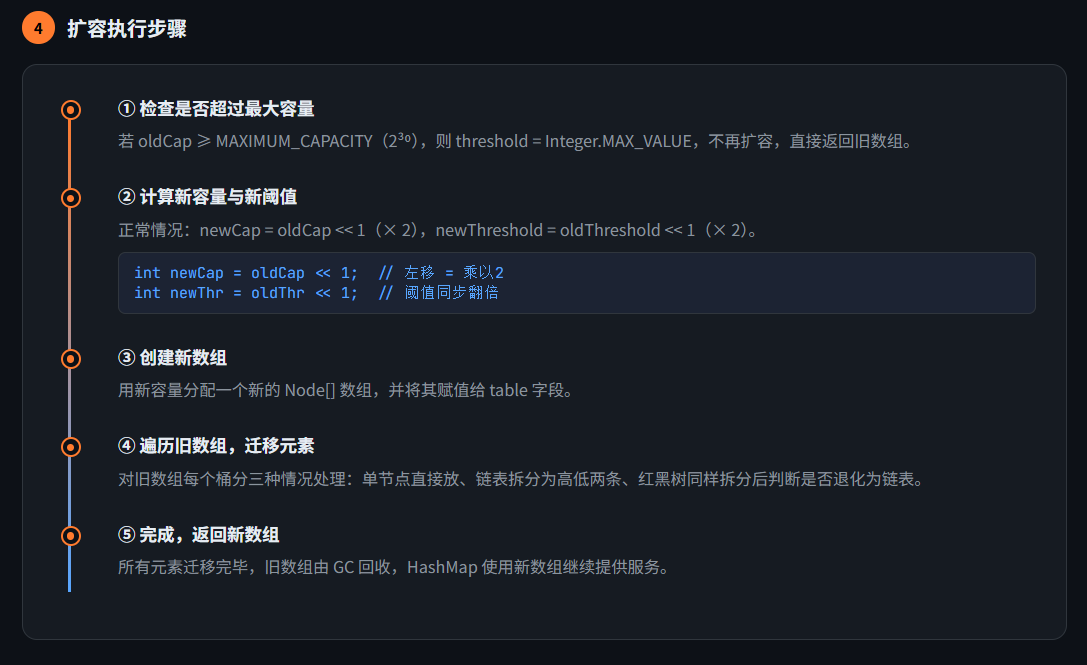
| 要点 | 说明 |
|---|---|
| 触发条件 | size > capacity × loadFactor |
| 扩容倍数 | 新容量 = 旧容量 × 2 |
| 迁移优化 | 高位 bit 判断,避免重新 hash |
| 链表/树处理 | 拆分为高低位两组,按长度决定链表或树 |
| 线程安全 | HashMap 非线程安全,并发请用 ConcurrentHashMap |
评论